-
为什么“正态分布”是SPC分析的重要基础?
从统计规律到斌果SPC中的实际应用——
在SPC(统计过程控制)、CPK过程能力分析以及质量管理中,“正态分布”是最核心的统计概念之一。
无论是控制图、过程能力分析,还是异常判异,很多经典统计模型都建立在正态分布基础之上。
很多制造企业每天都在使用:
- CPK
- 控制图
- SPC报警
- 过程能力分析
但却并没有真正理解:
为什么SPC分析如此依赖正态分布?
为什么很多CPK分析都默认数据必须“近似正态”?而这,恰恰决定了统计分析结果是否可靠。
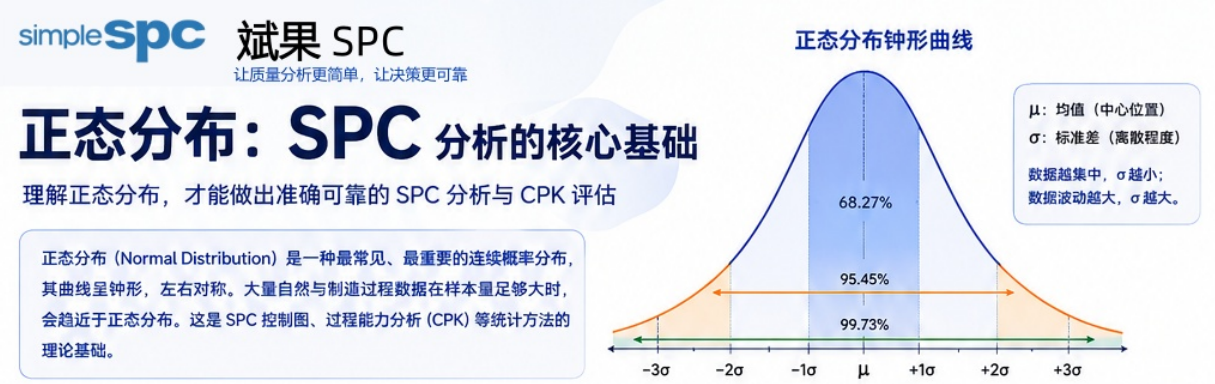
一、什么是正态分布?
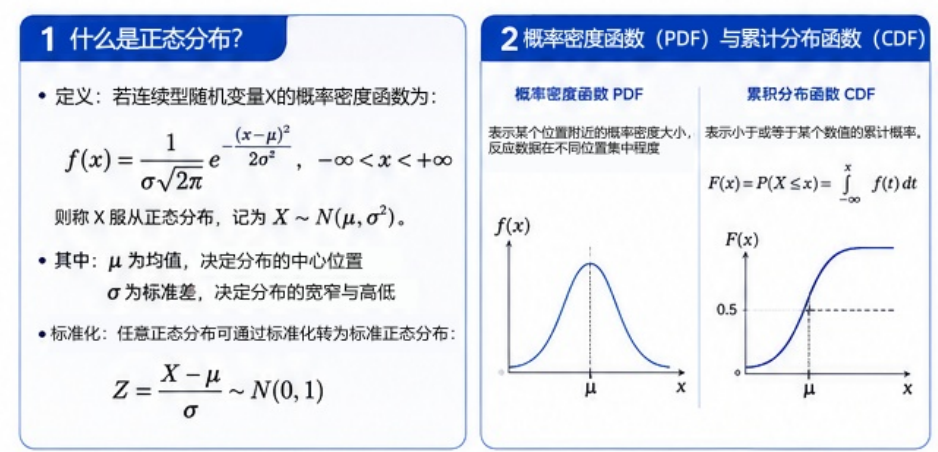
正态分布(Normal Distribution)是一种最常见、最经典的连续概率分布。
它最大的特征是:
- 中间高
- 两边低
- 左右对称
整体呈现出典型的“钟形曲线(Bell Curve)”。
在现实制造场景中,大量质量数据都会逐渐接近正态分布,例如:
- 产品尺寸
- 加工误差
- 涂覆厚度
- 材料重量
- 设备加工精度
- 工艺波动数据
虽然这些数据会受到大量复杂因素影响,但当样本量足够大时:
大多数数据通常会集中在平均值附近,而极端值相对较少。
这也是正态分布最典型的统计特征。
二、为什么正态分布对SPC如此重要?
SPC本质上是:通过统计规律判断生产过程是否稳定。
而很多经典SPC分析都默认:数据近似服从正态分布。
例如:
- 3 Sigma控制限
- CPK过程能力分析
- PPK分析
- 判异规则
- PPM缺陷率估算
都与正态分布密切相关。
经典统计规律中:
- ±1σ 覆盖约68.27%
- ±2σ 覆盖约95.45%
- ±3σ 覆盖约99.73%
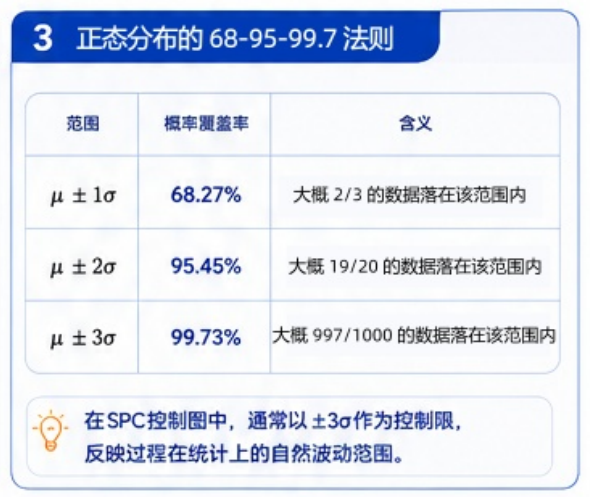
因此,SPC控制图中的:
- UCL(上控制限)
- LCL(下控制限)
通常建立在:
平均值 ± 3倍标准差
的基础上。

三、为什么现实生产数据容易接近正态分布?
在制造现场,一个质量特性往往同时受到多个随机因素影响,例如:
- 设备精度
- 刀具磨损
- 温度变化
- 材料差异
- 操作员习惯
- 设备振动
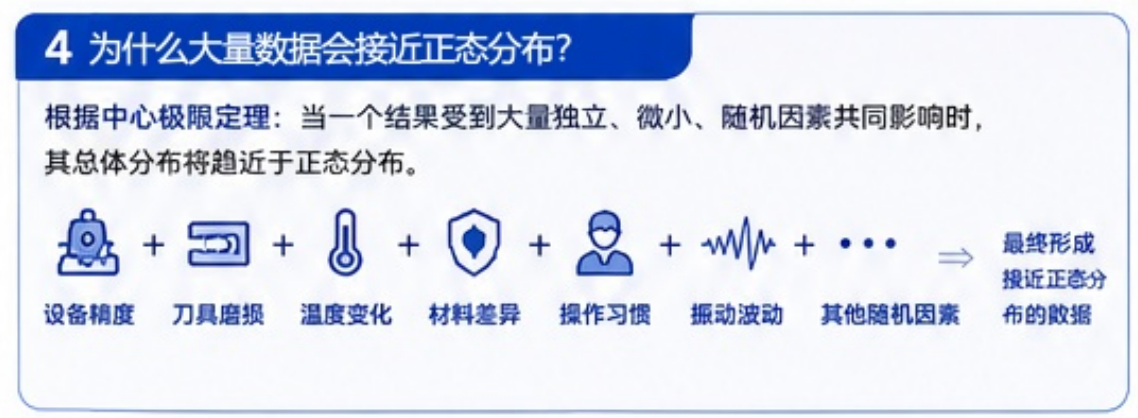
虽然单个因素影响有限,但大量随机波动叠加后:
最终会形成稳定的钟形分布。
因此,正态分布并不是人为规定出来的数学模型。
它实际上是:大量随机扰动共同作用后的自然统计结果。
这也是为什么正态分布会广泛出现在:
- 制造业
- 自然科学
- 金融
- 生物统计
等众多领域。
四、正态分布中的均值与标准差
正态分布最重要的两个参数:
1. 均值(Mean)
均值决定:数据中心的位置。
也就是钟形曲线最高点所在的位置。
2. 标准差(Standard Deviation)
标准差决定:数据波动大小。
标准差越大:
- 数据越分散
- 曲线越宽
标准差越小:
- 数据越集中
- 过程越稳定
在SPC分析中:标准差通常直接影响过程能力结果。
五、为什么CPK分析如此依赖正态分布?
CPK本质上是在衡量:制程波动是否能够稳定落入规格范围内。
而CPK计算过程中:
- 标准差
- 概率分布
- 尾部缺陷率
都建立在正态分布假设基础之上。
因此,如果数据严重偏离正态分布:
- CPK可能失真
- 控制限可能不合理
- SPC报警可能误报
- 过程能力可能被错误评估
这也是很多企业出现:“SPC一直报警,但现场没人处理”的重要原因之一。
并不是所有制造数据都天然符合正态分布
很多传统SPC软件默认:所有数据都服从正态分布。
但现实制造过程中,并非所有数据都满足这一条件。例如:
- 寿命测试数据
- 化工数据
- 电池容量数据
- 半导体工艺数据
- 厚度类数据
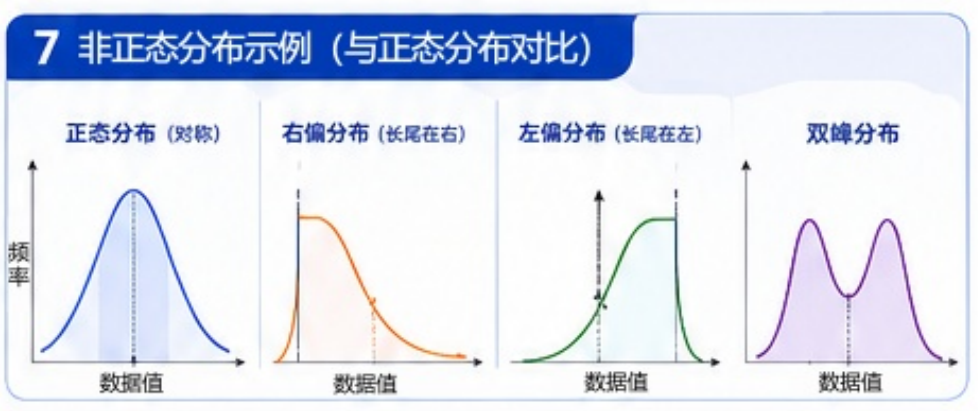
经常会出现:
- 偏态分布
- 长尾分布
- 多峰分布
如果仍然直接使用传统CPK分析,就可能导致:
- 过程能力误判
- 虚假的质量结论
- 不合理的SPC分析结果
因此,在进行CPK分析之前:
数据是否满足正态分布条件,本身就是非常重要的统计前提。
六、斌果SPC中的非正态数据分析能力
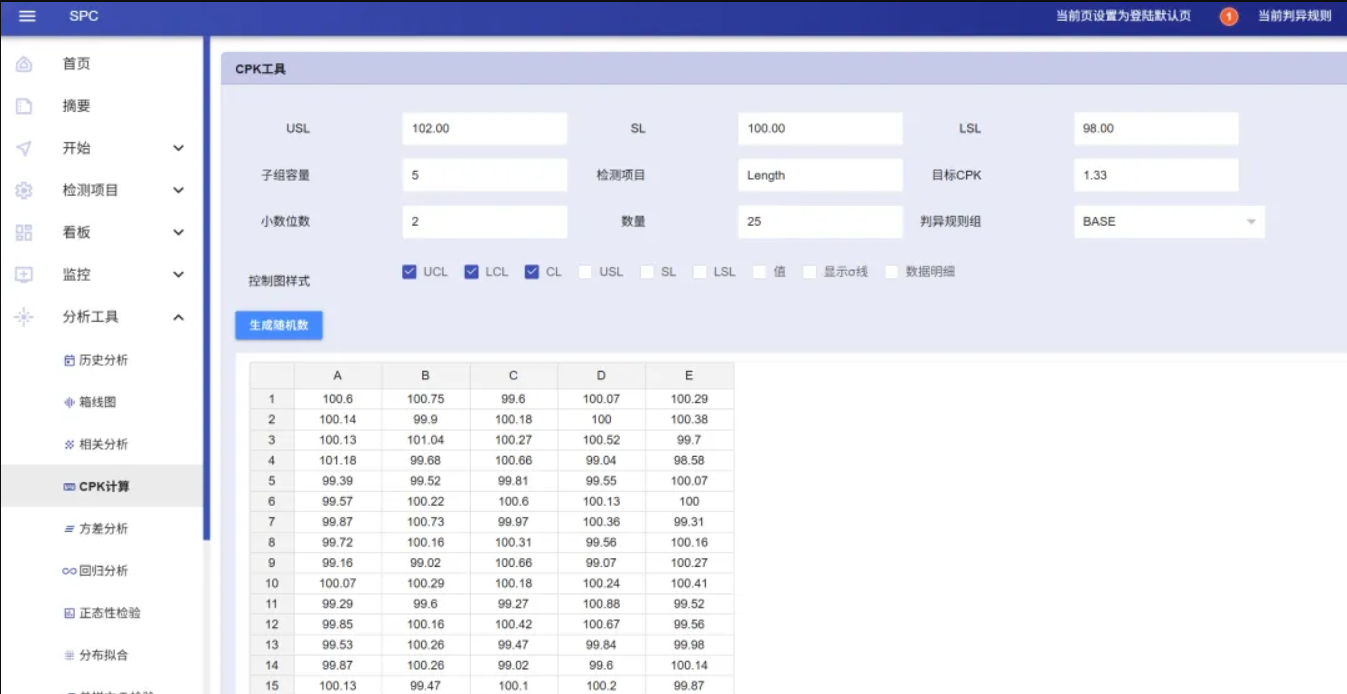
针对复杂制造场景,斌果 SPC 提供了独立的 CPK 分析工具,支持非正态数据分析。
用户可通过导入数据,在 CPK 工具中进行:
- 非正态分布分析
- Box-Cox转换
- 分布拟合
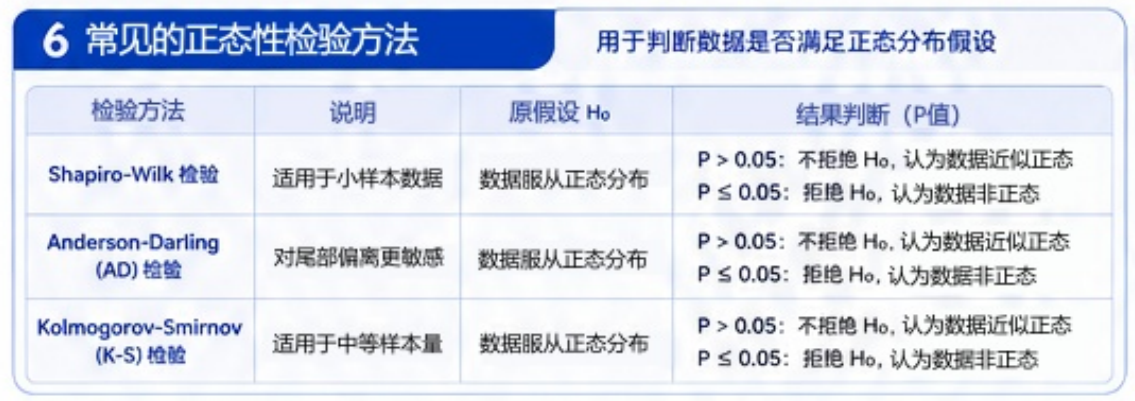
- 正态性检验
- AD检验
- P值分析
帮助质量工程师评估:当前数据是否适合直接进行传统CPK过程能力分析。

独立CPK工具中的正态性分析
在 斌果 SPC 的独立 CPK 工具中,系统可自动生成:
- 正态概率图
- AD统计量
- P值结果
帮助质量工程师快速判断:数据是否满足传统CPK分析所需的正态分布条件。
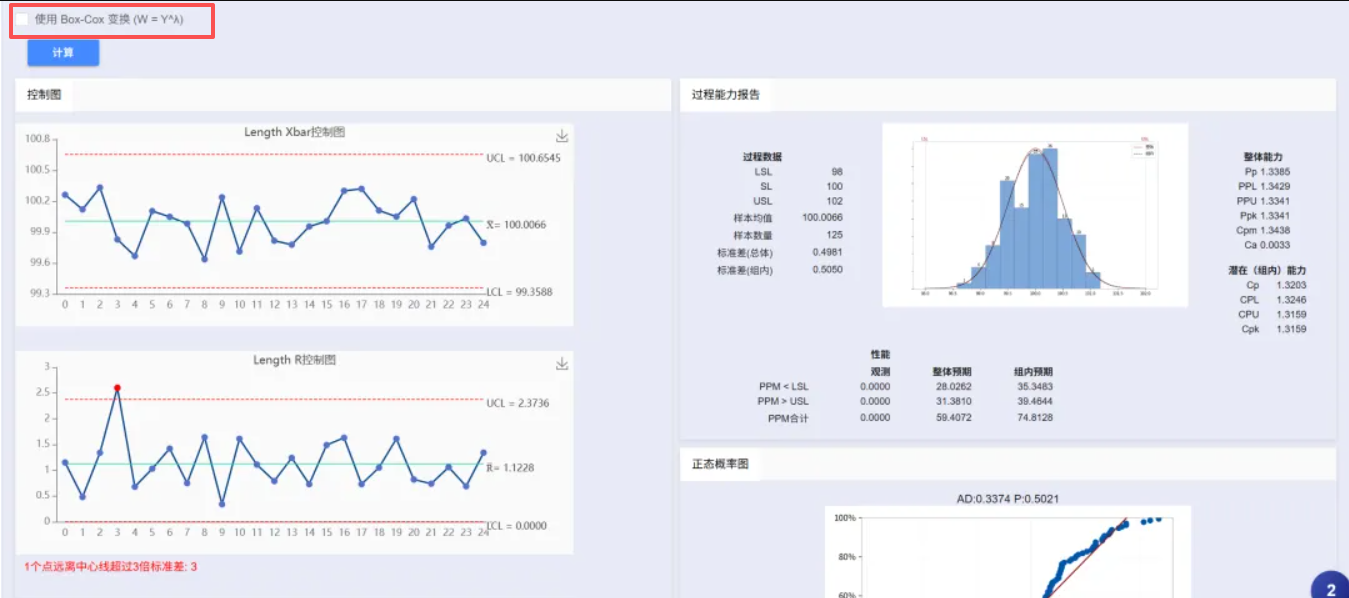
同时系统支持:
- Normal
- Lognormal
- Weibull
等多种分布拟合分析。尤其适用于:
- 半导体
- 电池制造
- 医疗器械
- 化工行业
- 寿命测试场景
等复杂制造行业。

七、为什么现代SPC越来越重视非正态分析?
随着智能制造的发展,越来越多企业开始意识到:
并不是所有质量数据都天然符合正态分布。
因此,现代SPC系统不仅需要:
- 控制图
- CPK分析
- 判异规则
更需要:对数据本身进行统计真实性验证。
这也是现代质量管理与传统SPC分析的重要区别之一。
八、正态分布不仅是一条经典的钟形曲线
它更是:SPC、CPK以及现代质量统计分析的重要理论基础。
理解正态分布,企业才能真正理解:
- 为什么会出现SPC异常
- 为什么CPK会失真
- 为什么控制图会误报
- 为什么需要非正态分析
通过 斌果 SPC 的独立 CPK 分析工具,企业可以进一步完成:
- 正态性检验
- 分布拟合
- 非正态数据分析
- 过程能力研究
帮助质量工程师建立更加真实、可靠的数据分析基础。

本页面文章与公众号同步。

微信扫码关注